K.C.S.E Physics Q & A - MODEL 2005PP1QN11
Fig 8 shows water drops on two surfaces. In 8 (a) the glass surface is smeared with wax while in 8 (b) the glass surface is clean.
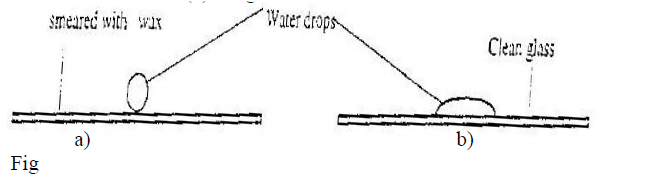
Explain the difference in the shapes of the drops.
answer
0 Comments
K.C.S.E Physics Q & A - MODEL 2003PP1QN11
One of the factors that affect the surface tension of a liquid is the presence of impurities. State one other factor.
answer
K.C.S.E Physics Q & A - MODEL 2003PP1QN03
Figure 3 shows two identical trolleys with loads A and B. The loads are identical in shape and size.

Given that the density of A is greater than that of B, explain why the trolley in figure 3(ii) is more suitable.
answer
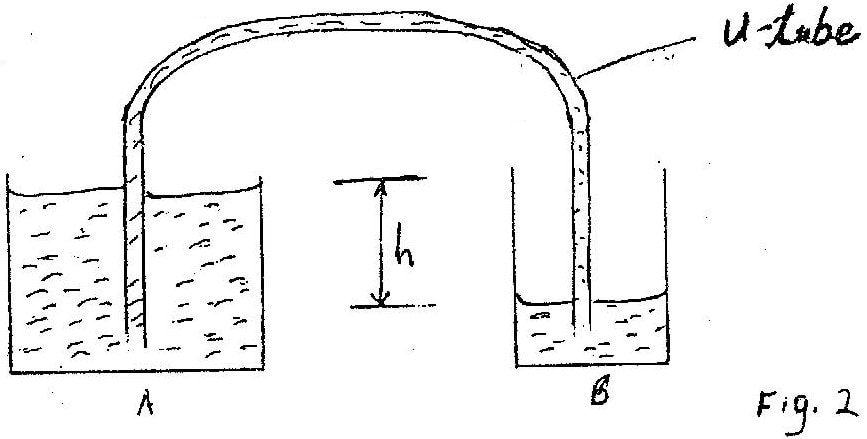
K.C.S.E Physics Q & A - MODEL 2003PP1QN02
Two identical spring balances R and S each weighing 0.5N are arranged as shown in Figure 2.
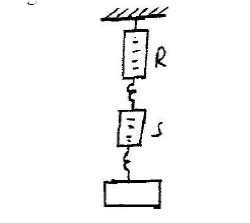
What is the reading on balance R?
answer
K.C.S.E Physics Q & A - MODEL 2002PP1QN20
A high jumper usually lands on thick soft mattress. Explain how the mattress helps in reducing the force of impact.
answers
K.C.S.E Physics Q & A - MODEL 2002PP1QN10
Fig. 5 shows a wire A and a spring B made of the same material. The thickness of the wire is the same in the both cases. Masses are added on each at the same intervals and the extension noted each time.
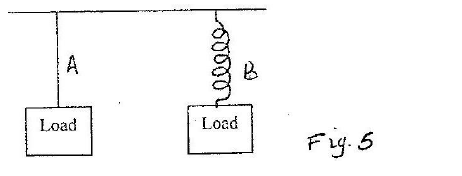
On the same axes provided, sketch the graphs of extension against load for each. (hookers law is obeyed.)

answers
K.C.S.E Physics Q & A - MODEL 2001PP2QN03
a) a hole of area 2.0 cm2 at the bottom of a tank 2.0m deep is closed with a cork. Determine the force on the cork when the tank is filled with water. (Density of water is 1000kg/m3 and acceleration due to gravity is 10m/s2).
answers

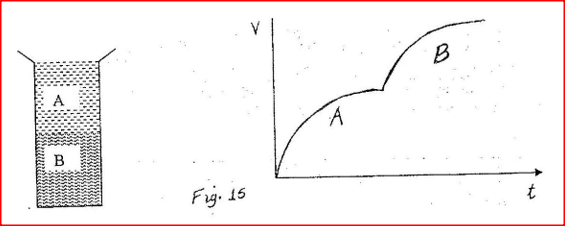
K.C.S.E Physics Q & A - MODEL 2001PP1QN22
Fig. 15 shows a tall jar containing two fluids A and B. The viscosity of A is higher than that of B. A solid sphere is released at the top of the jar and falls through the fluids.
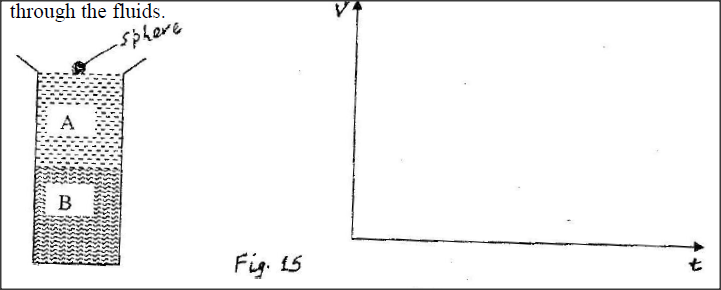
On the axes provided, sketch the velocity – time graph for the motion of the spheres through the fluids.
answer
K.C.S.E Physics Q & A - MODEL 2001PP1QN06&7
Fig. 5 shows a flask fitted with a glass tube dipped into a beaker containing water at room temperature. The cork fixing the glass tube to the flask is airtight.
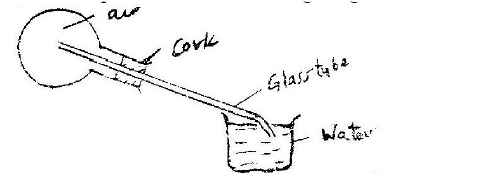
Use the information and the figure to answer questions 6 and 7.
State what is observed when ice- cold water is poured on the flask. Give a reason for the observation in question 6.
answers
K.C.S.E Physics Q & A - MODEL 2001PP1QN05
Fig. 4 (i) shows a beaker filled with water. Some potassium permanganate was gently introduced at the bottom of the beaker at the position shown.
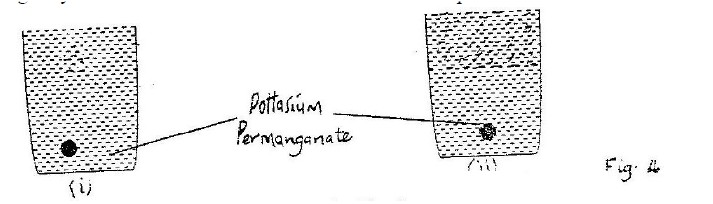
Fig. 4(ii) shows the appearance of the liquid after about 30 minutes. Explain how this appearance was caused.
answer
K.C.S.E Physics Q & A - MODEL 1999PP1QN29
A concrete block of volume V is totally immersed in seawater of density p. Write an expression for the up thrust on the block.
ANSWER
K.C.S.E Physics Q & A - MODEL 1999PP1QN05
Fig. 4 shows a capillary tube placed in though of mercury.

Give a reason why the level of mercury in the capillary tube is lower than in the beaker.
ANSWERS
K.C.S.E Physics Q & A - MODEL 1998PP1QN05
A metal pin was observed to float on the surface of pure water. However the pin sank when a few drops of soap solution were carefully added to the water. Explain his observation.
ANSWER
K.C.S.E Physics Q & A - MODEL 1997PP1QN08
State the reason why water spilled on a glass surface wets the surface
answers
K.C.S.E Physics Q & A - MODEL 1997PP1QN03
Give a reason why the weight of the body varies from place to place
answer
K.C.S.E Physics Q & A - MODEL 1997PP1QN02
Figure 2 shows a rigid body acted upon by a set of forces. The magnitudes of the forces are as follow
F1 = 3N1, F2 = 6N, F3 = 3N, F4 = 4 N1, F5 = 3N and F6 = 3 N 
Identify the couple among these forces
answers
K.C.S.E Physics Q & A - MODEL 1996PP1QN16
Sketch in the space provided below, a labeled diagram to show how an arrangement of a single pulley may be used to provide a mechanical advantage of 2
answers
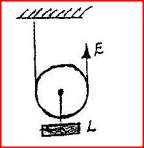
 The diagram in figure 5 shows a beam negligible weight balanced by constant forces P and Q. Derive the relationship between x and y K.N.E.C Marking Scheme
At equilibrium sum of clockwise moment = sum of anti – clockwise moments |
CATEGORIES
Categories
All
Topics
FORM I - PHYSICS SYLLABUSFORM II - PHYSICS SYLLABUSTOPICS
FORM III - PHYSICS SYLLABUSFORM IV - PHYSICS SYLLABUSARCHIVES
RSS FEEDS
AUTHOR
M.A NyamotiMy passion is to see students pass using right methods and locally available resources. My emphasis is STEM courses
|


 RSS Feed
RSS Feed